* Youtube Link - https://www.youtube.com/watch?v=qqgCwZ81tTs&list=PLVsNizTWUw7FzFgU1qe-n7_M7eMFA9d-f&index=23
대용량 데이터의 경우 인덱스가 없이는 사용이 불가능한 경우가 많다.
9.1 인덱스의 개념

'폭포수 모델'을 찾으려면 책 전체를 찾아봐야 한다.
하지만 책의 찾아보기를 사용을 하면 쉽게 page를 찾을 수 있다.
이것이 바로 인덱스다.
500page를 뒤져서 찾던 것을 간단히 11page안에 찾는다. 엄청나게 효율이 좋다.
인덱스의 장점 및 단점

단점:
- 인덱스를 추가하면 분량이 늘어난다. (10%정도 차지한다.)
- 인덱스가 있다고 무조건 쓰는 것은 아니다. 찾는 데이터가 많다면, 인덱스를 왔다 갔다 하면 호율이 훨씬 악화된다.
- 데이터의 변경 작업에서는 성능이 오히려 나빠진다. 인덱스에도 추가를 해야하기 때문이다.
인덱스에 대한 이해가 굉장히 많이 필요하다.
장점:
- 검색의 속도가 굉장히 빨라질 수 있다.
- 전체 시스템의 성능이 향상이 된다. (사용자 수가 늘어나면 성능의 향상이 곱하기로 늘어난다.)
인덱스를 많이 만들면 오히려 악화된다.
데이터의 분포를 이해하고 적절하게 인덱스를 만들어야 한다.
인덱스의 종류

B-TREE 인덱스와 BITMAP 인덱스, 함수기반 인덱스, 어플리케이션 도메인 인덱스로 나뉜다.
특수한 테이블인 Index-Organized 테이블로 나뉜다.
가장 일반적인 인덱스는 B-TREE 인덱스이다.
- 자동으로 생성되는 인덱스

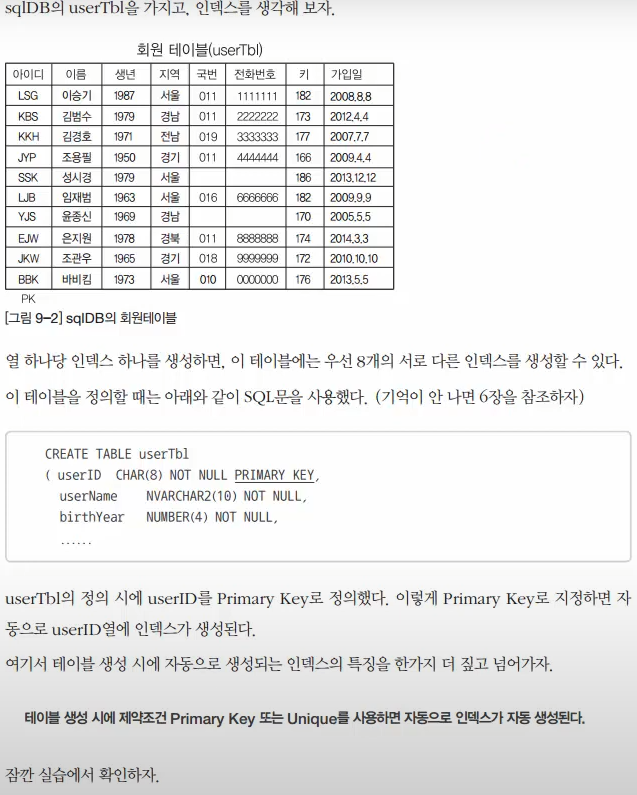
하나씩 하나당 인덱스를 한다.
여러 컬럼을 조합해서 인덱스를 할 수도 있다.
테이블 생성 시에 제약조건 Primary Key 또는 Unique를 사용하면 자동으로 인덱스가 자동 생성된다.
- USER_INDEXES 및 USER_IND_COLUMNS

SELECT I.INDEX_NAME, I.INDEX_TYPE, I.UNIQUENESS, C.COLUMN_NAME, C.DESCEND
FROM USER_INDEXED I
INNER JOIN USER_IND_COLUMNS C
ON I.INDEX_NAME = C.INDEX_NAME
WHERE I.TABLE_NAME = 'TBL1';
- INDEX_TYPE이 NORMAL이면 B-TREE INDEX이다.
- UNIQUENESS가 UNIQUE이면 중복 허용이 안된다는 의미이다.
- COLUMN_NAME을 통해서 열 이름을 확인할 수 있다. A열이 PK이다.
- DESCEND가 ASC 이므로 정렬이 오름차순으로 되어있는 것을 볼 수 있다.

A 컬럼은 PRIMARY KEY, B 컬럼은 UNIQUE, C 컬럼은 UNIQUE로 정의하였다.
3개의 자동 생성 인덱스가 자동 생성된 것을 볼 수 있다.
자동으로 생성된 인덱스들은 테이블의 제약조건이 삭제되면 자동으로 삭제된다.
감사합니다.
'Oracle' 카테고리의 다른 글
| [이것이 오라클이다] 09장 3교시: [Oracle] 인덱스의 생성/변경/삭제 (1) | 2024.11.07 |
|---|---|
| [이것이 오라클이다] 09장 2교시: [Oracle] 인덱스의 내부 작동 (2) | 2024.11.07 |
| [이것이 오라클이다] 08장 4교시: [Oracle] 뷰, 구체화된 뷰 (3) | 2024.11.06 |
| [SQLD] 최신 기출문제 2회 (11~20) (3) | 2024.11.06 |
| [이것이 오라클이다] 08장 3교시: [Oracle] 임시 테이블 및 테이블 삭제/수정 및 제약 조건 실습 (2) | 2024.11.05 |