* Youtube Link - https://www.youtube.com/watch?v=lHLx-V76fiA&list=PL6i7rGeEmTvpLoDkB-kECcuD1zDt_gaPn&index=7
1. CRUD 매트릭스

행과 열의 매트릭스 방식으로 보여주는 것을 CRUD 매트릭스라고 한다.
그래서 프로세스와 CRUD간의 상관 관계를 알아볼 수 있는 것이다.
데이터와 프로세스의 상관 관점이다.
2. 속성의 분류

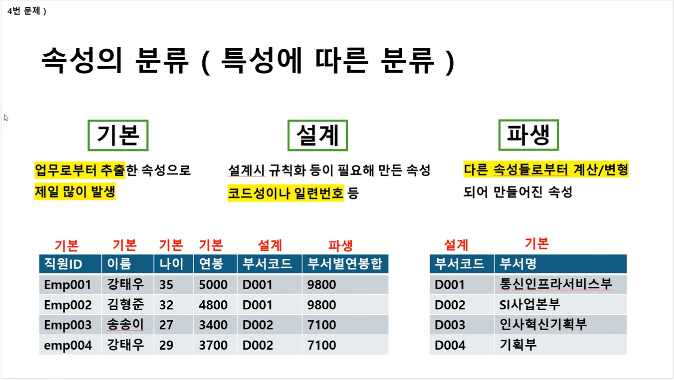

시, 구, 동, 호를 나누면 어려울 것이다.
그래서 복합하여 사용한다.
이러한 내용을 복합 속성이라고 한다.
3. 데이터베이스 3단계 구조


스키마는 관점이라고 보면 된다.
4. 반정규화


논리적 데이터 모델링을 할 때 정규화를 필수적으로 한다.
반정규화는 정규화의 반대 개념이다.
중복을 허용하고, 이상한 현상이 발생할 수 있는 상태를 의미.

데이터를 수직 분할하는 이유는 데이터를 100개 출력할 때 컬럼이 많으면 컬럼이 낭비가 된다.
만약에 테이블을 분리했는데, 데이터를 입력해야 한다면 두 테이블 모두 입력을 해주어야 한다.

조인을 하는데 성능을 더 낮게 만드는 경우가 있다.
5. 슈퍼/서브 타입 데이터 모델


고객이 슈퍼타입이고 서브타입의 공통적인 속성을 갖는다.
개인고객 그리고 법인고객은 서브타입으로 서로 배타적 관계를 갖는다.
즉 개인고객의 고객번호와 법인고객의 고객번호는 서로 같을 수 없다.
예를 들어 개인고객 고객번호는 1,3,5가 입력되면
법인고객 고객번호는 2,4,6이 입력되는 것이다.
조인이 발생하고 관리가 어렵다.

이렇게 하나로 모아서 관리를 하면 편하겠지만
개인고객 또는 법인고객만 조회를 해야 할 때 전체를 스캔해야 하는 현상이 발생합니다.
SELECT할 때 성능이 안 좋을 수 있습니다.

전부 다 개별적으로 테이블을 생성을 하는 것.
테이블의 수가 많고 조인이 많이 발생해 관리가 어렵다.
6. 카디널리티


선택도란 전체 테이블 개수 중에서 내가 뽑고자 하는 개수의 비율이다.
SELECT * FROM TB_CUST WHERE MONEY = 10000; -- 전체 7개 행 중에 2개
선택도: 2/7 == 0.285...
카디널리티(출력된 행의 수) : 선택도 X 전체 레코드수 => 0.285 X 7 => 2
7. 데이터 정규화


2차 정규화란
PK A,B를 조합하여 인스턴스 나머지 컬럼 C,D,E를 조회할 수 있다.
여기서 PK A만으로도 나머지 컬럼들을 조회하여 유일하게 식별할 수 있다면
이를 부분 종속성이라고 하여 분리해주어야 한다.
3차 정규화란
컬럼에서 예를 들어 A,B,C,D,E가 있는데
D가 부서코드이고 E가 부서명이며 D가 E를 유일하게 식별할 수 있으면
이를 이행종속성이라고 한다.
테이블을 분리해주어야 한다.
8. ERD

IE 표현 기법이다.
PK (식별자)는 중복 x, null x
정답은 3번이다.
감사합니다.
'SQLD' 카테고리의 다른 글
| [SQLD] 최신 기출문제 1회 (21~30) (5) | 2024.11.05 |
|---|---|
| [Youtube review] [SQLD] 최신 기출문제 1회(11~20) (4) | 2024.10.31 |
| [Youtube review] [SQLD] 핵심 이론 강의 06회 (2) | 2024.10.31 |
| [Youtube review] [SQLD] 핵심 이론 강의 05회 (2) | 2024.10.31 |
| [Youtube review] [SQLD] 핵심 이론 강의 04회 (2) | 2024.10.31 |