안녕하세요, 유튜브 SQL 튜닝 강의를 보고 학습한 자료를 남깁니다.
감사합니다.
실습

테이블 생성을 하였다.

성능 소요시간을 확인해보니 499/ms 정도 된다.

created_at 컬럼에 인덱스를 생성하니
소요시간이 167/ms로 단축되었다.
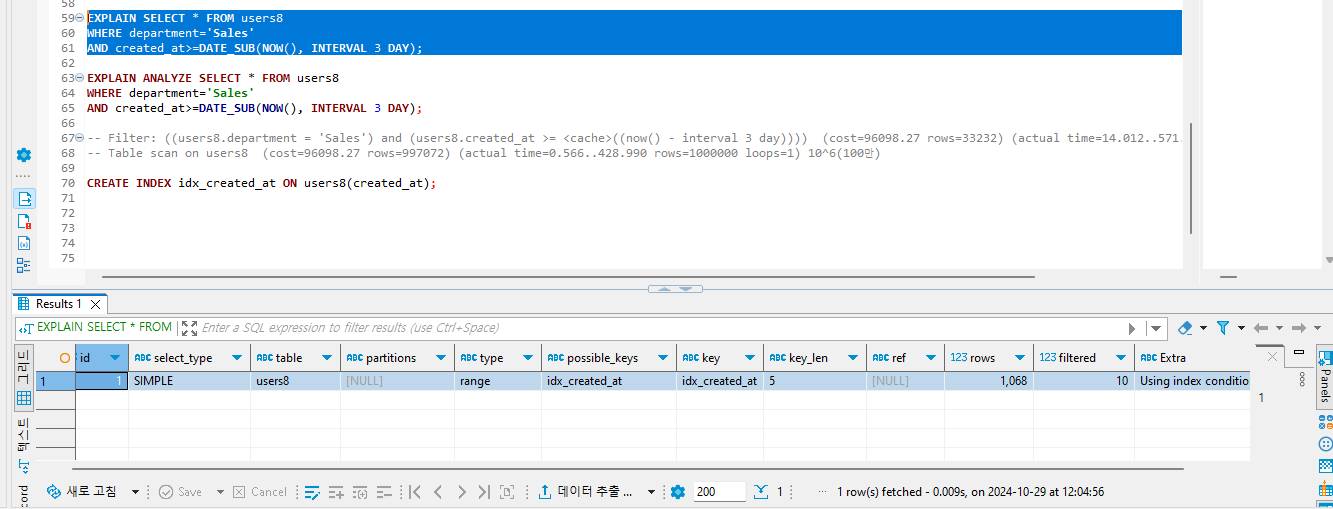
type을 통해 인덱스 레인지 스캔이 이루어진 것을 볼 수 있었다.
그리고 rows는 1,068 정도 조회된 것을 확인할 수 있다.

-> Filter: (users8.department = 'Sales') (cost=1174.84 rows=107) (actual time=4.144..135.122 rows=108 loops=1)
-> Index range scan on users8 using idx_created_at, with index condition: (users8.created_at >= <cache>((now() - interval 3 day))) (cost=1174.84 rows=1067) (actual time=1.616..134.444 rows=1067 loops=1)
INDEX RANGE SCAN을 했는데 날짜 값의 조건을 만족하는 인덱스들 만을 가져온다. 1067행을 조회하였고 접근한 수 자체가 적다보니 134ms밖에 안 걸렸다.
이렇게 해당하는 값들을 가져오고 그 다음에 Filtering 작업을 거친다. 날짜 조건을 만족하는 데이터들 중에서 department='Sales' 인 값들을 가져온 것이다. rows=108이므로 총 108개의 데이터가 출력이 될 것이다.
속도가 왜 빨라졌어? 아 INDEX RANGE SCAN으로 딱 필요한 데이터에 대해서만 접근을 했기 때문에 속도가 빨라졌구나 추측을 할 수 있다.

이번에는 department 컬럼에 인덱스를 생성하고
조회를 해 보았다.
소요 시간이 2,157ms가 소요되는 것을 볼 수 있다.

-> Filter: (users8.created_at >= <cache>((now() - interval 3 day))) (cost=15571.68 rows=63765) (actual time=23.752..2113.186 rows=106 loops=1)
-> Index lookup on users8 using idx_department (department='Sales') (cost=15571.68 rows=191314) (actual time=9.402..2092.389 rows=100000 loops=1)


옵티마이저가 두개의 인덱스 중 더 효율적인 인덱스를 골라서 INDEX RANGE SCAN을 적용하였다.
한 개의 인덱스만 사용을 하였다.
1,043rows를 확인했다.

따라서 중복 정도가 낮은 컬럼을 골라서 인덱스를 생성하라.
항상 실행 계획을 보면서 판단을 하면 좋다.
멀티 컬럼 인덱스

기존의 인덱스를 모두 지우고
인덱스의 순서를 created_at 그리고 department 순으로 만들었다.
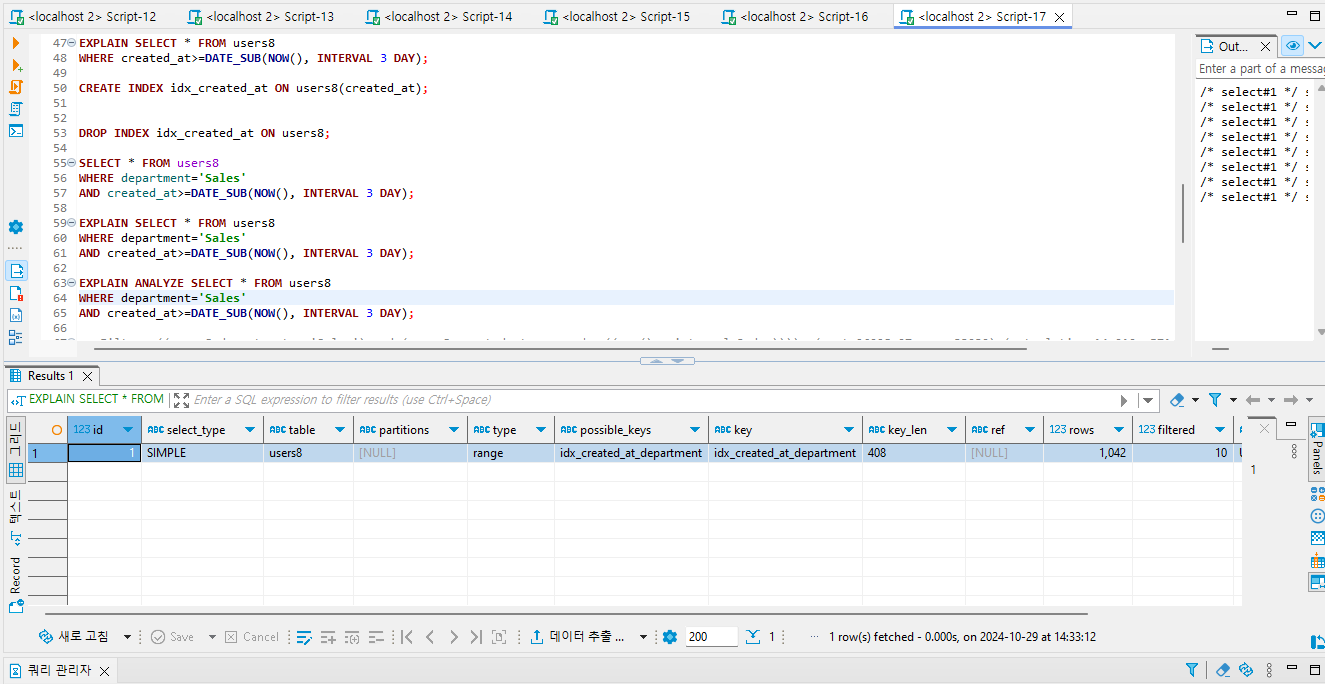
SELECT 시 조회 성능이 매우 좋은 것을 볼 수 있다.

이번에는 인덱스 순서를 바꾸어서
department, created_at 순서로 멀티 컬럼 인덱스를 생성해보았다.
비슷한 성능을 내는 것을 볼 수 있다.
멀티 컬럼 인덱스 사용 시 소요 시간이나 created_at 컬럼에 인덱스를 활용시 소요 시간이나 비슷한 것을 볼 수 있다.
이런 경우 created_at 인덱스에만 인덱스를 사용을 하는 것이 좋다.
왜냐하면 인덱스를 최소한으로 거는 것이 더 중요하기 때문이다.

정말 감사합니다.
https://www.youtube.com/watch?v=BpWzWoS9f1g&list=PLtUgHNmvcs6rJBDOBnkDlmMFkLf-4XVl3&index=16
'친절한 SQL 튜닝' 카테고리의 다른 글
| [친절한 SQL 튜닝] 12강) WHERE문이 사용된 SQL문 튜닝하기 - 1 (2) | 2024.10.29 |
|---|---|
| [친절한 SQL 튜닝] 11강) [실습] 한 번에 너무 많은 데이터를 조회하는 SQL문 튜닝하기 (1) | 2024.10.29 |
| [친절한 SQL 튜닝] 10강) SQL문의 '실행 계획' 사용해보기 (EXPLAIN) (0) | 2024.10.29 |
| [친절한 SQL 튜닝] 8,9강) 자동 생성 인덱스 (4) | 2024.10.29 |
| [친절한 SQL 튜닝] 7강) [실습] 인덱스 직접 설정해보기 / 성능 측정해보기 (1) | 2024.10.29 |

































