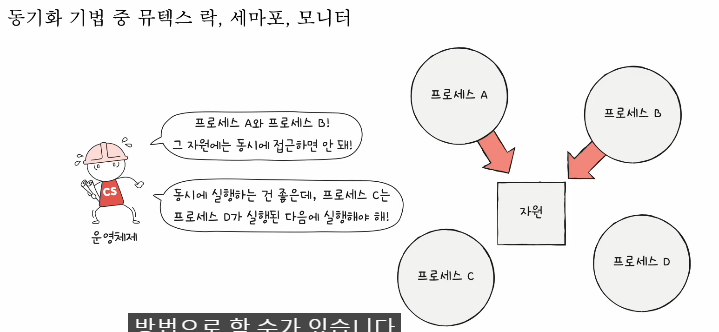
안녕하세요, 혼자 공부하는 컴퓨터 구조 + 운영체제를 공부하고 학습한 자료를 남깁니다.
- 들어가며

- 파티셔닝

구입된 새 하드 디스크 / SSD 는 파티셔닝, 포매팅 하기 전까지 사용할 수 없다.

서랍안에 물건을 보관할 때 정리해서 보관해야 한다. 이러한 일을 해야 한다.

필요한 물건을 찾기가 용이해진다.
용량이 큰 저장 장치를 하나 이상의 논리 단위로 구획하는 작업이다. 구분된 영역 하나 하나를 파티션이라고 부른다.

각각의 파티션을 확인할 수 있다.
하나의 영역이 구획되어 있다.
- 포매팅

파일 시스템을 설정하고, 어떤 방식으로 파일을 관리할지 결정하고, 새로운 데이터를 쓸 준비를 하는 작업이다.

USB를 포매팅하는 장면이다. 용량은 어느 정도 되는지, 파일 시스템은 어떻게 되는지를 설정할 수 있다.
포맷할 때 파일 시스템이 결정된다.

파티션 마다 다른 파일 시스템을 사용할 지를 다르게 설정할 수 있다.
포매팅까지 완료가 되면 파일 시스템을 설정 했다면 파일과 디렉터리 생성이 가능해진다.
- 파일 할당 방법

섹터를 블록 단위로 묶어서 관리하게 된다.

네모는 블록의 위치를 식별하는 주소라고 본다.
블록의 위치에 파일을 할당할 것이다. 큰 파일은 여러 개의 블록에 걸쳐 저장이 될 것이다. 작은 파일은 적은 블록에 걸쳐 저장이 될 것이다.

- 연속 할당

단순하게 보조기억장치에 연속해서 파일을 저장하는 방식이다.


연속 할당은 외부 단편화를 야기할 수 있다.

파일이 삭제 되었을 때, 잔여 블록에 새로운 파일을 할당하기 힘들다.
- 불연속 할당 방법 - 연결 할당


조회할 수 있는 다음 블럭이 없는 경우 특별한 표시자를 붙여서 이 블록이 파일의 끝임을 나타낸다. 여기서는 -1이라고 표시하고 있다.

결과적으로 단점은 참조하는 블록이 많으므로 접근 속도가 매우 드리다. (자료 구조의 연결 리스트의 단점과 동일하다.)
순차적으로 접근을 해야만 한다. 성능면에서 아주 비효율적이다.
하드웨어 고장이나 오류가 발생을 하면 해당 블록에 접근을 할 수가 없다.
- 불연속 할당 - 색인 할당

하나의 색인 블록이 모든 파일의 주소들을 기록하고 있다.
연결 할당 기법보다 파일의 임의의 위치에 접근하기가 용이하다.

- 파일 시스템 살펴보기 - FAT 파일 시스템

USB, SSD 등 저용량 장치에서 주로 사용되는 파일 시스템이다.
연결 할당 기반의 파일 시스템이다. 연결 할당 기법의 단점을 보완하는 방식이다.

각 블록에 포함된 다음 블록 주소를 한데 모아 테이블로 관리
File Allocation Table이다.
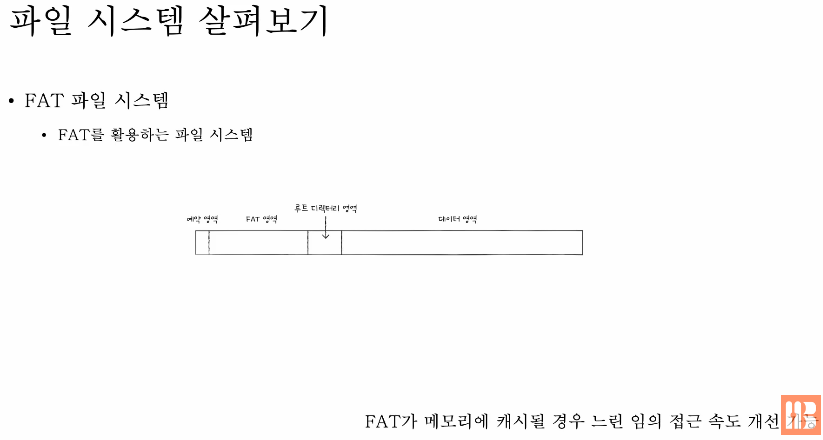
MS-DOS에서 많이 사용 되었고
FAT12, FAT16, FAT32 등은 블록을 의미하는 비트 수를 의미합니다.
FAT가 메모리에 캐시될 경우 느린 임의 접근속도를 개선을 할 수가 있다.
기존의 문제점들을 해결할 수 있다.
위 그림은 FAT파일 시스템의 파티션을 간략화한 도식도이다.
예약 영역(파일 시스템에 필요한 기능들이 미리 예약되어 저장되는 영역) / FAT 영역 / 루트 디렉터리 영역 (루트 디렉터리가 저장되는 영역) / 데이터 영역 (각종 파일들이 관리되기 위한 영역)

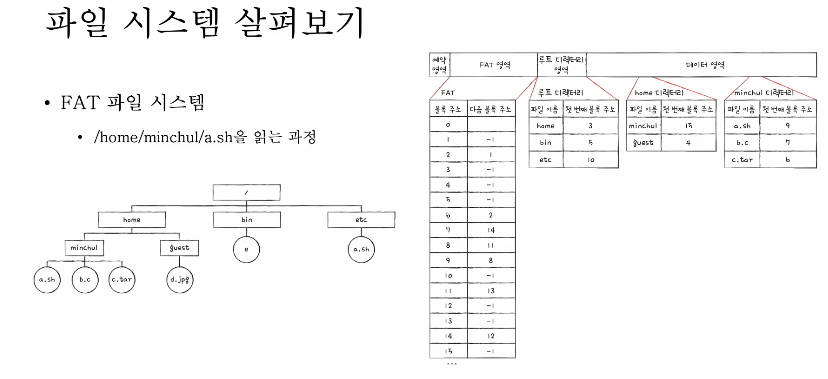
가장 먼저 루트 디렉터리부터 접근을 해야 될 것이다. 홈 디렉터리는 3번 블럭에 있다. 3번 블럭을 읽어서 home 디렉터리를 보니까 15번 블럭에 저장되어 있는 것을 알 수 있다. 그래서 minchul 디렉터리에서 a.sh의 9번 블럭을 읽을 수 있다. FAT 9번 블럭으로 가서 연결된 블럭들을 읽어서 파일에 접근하게 된다. -> /home/minchul/a.sh을 읽는 과정
- 파일 시스템 살펴보기 - 유닉스 파일 시스템 (색인 할당 기반 파일 시스템)
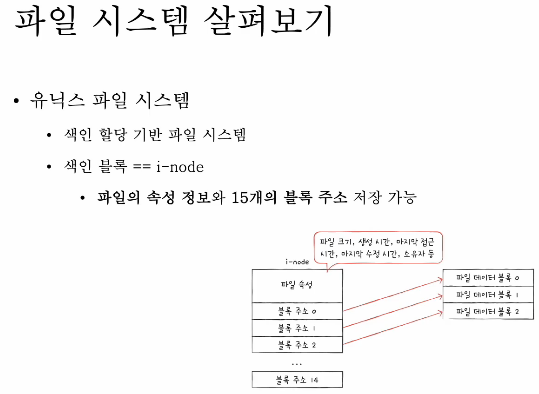
i-node는 파일의 속성 정보와 15개의 블록 주소 저장 가능
파일마다 이러한 i-node를 갖고 있고, i-node마다 고유한 번호를 갖고 있다.
i-node가 유닉스 시스템에서 가장 중추적인 역할을 한다.

i-node들이 하나의 파티션에 저장되어 있다.
만약에 15개 파일보다 큰 파일의 주소를 저장해야 한다면 어떻게 해야 할까?

12개에는 파일의 직접 블록 주소 저장을 입력하게 된다.

만일 13번째 부터 주소가 부족하다면, 12번째 블록 주소에 단일 간접 블록 주소를 저장한다.
만일 이로도 충분하지 않다면

14번째 블록에 이중 간접 블록 주소를 저장한다.

만일 이로도 충분하지 않다면 15번째 주소에 삼중 간접 블록 주소를 저장한다.
여기까지만 와도 왠만한 크기의 파일들은 모두 저장할 수 있게 된다.
유닉스 파일은 i-node만 알아도 파일의 속성과 파일의 위치를 전부 다 알 수 있다. 파일의 크기가 커도 마찬가지다.
i-node가 가장 중추적인 역할을 하고 있다. 파일 이름 외에 모든 것을 갖고 있다.

파일 이름과 i-node 번호만 알아도 어떤 크기의 파일도 알아볼 수 있다.

다음은 예제이다.
i-node에는 블록주소만 갖고 있다.
루트 디렉터리에 가장 먼저 접근을 해야 한다. 루트 디렉터리 접근을 위한 i-node를 항상 기억하고 있다. 2번 노드에 접근해서 1번 블록에 접근해야 한다는 것을 알 수 있다. 그럼 루트 디렉터리에서 3번 노드를 확인해야 함을 알 수 있다. 가서 210번 블록을 확인하면 home 디렉터리를 알 수 있고, 8번 노드에 minchul 디렉터리가 있음을 알 수 있다. 8번 노드로 접근을 해서 121번 블럭에 minchul 디렉터리가 저장되어 있음을 알 수 있다. 다시 minchul 디렉터리로 가서 a.sh이 9번 노드에 저장되어 있음을 알 수 있다. 그럼 9번 노드로 가서 해당 색인을 읽어 a.sh을 읽는다.
파일 시스템만을 다루는 전공서가 있으므로, 파일 시스템이 무엇인지 어떻게 블록을 통해서 파일과 디렉터리를 관리하는지 그리고 대표적으로 어떤 기법으로 접근하는지를 보았다.
NT-FX, EXT 파일 시스템 등도 알아보면 좋다.
감사합니다.
참고 url - https://www.youtube.com/watch?v=C-IYRzC-GW8&list=PLYH7OjNUOWLUz15j4Q9M6INxK5J3-59GC&index=45
'혼자 공부하는 컴퓨터 구조 및 운영체제 (복습)' 카테고리의 다른 글
| [운영체제] 파일과 디렉터리 (3) | 2024.10.19 |
|---|---|
| [운영체제] 페이징의 이점과 계층적 페이징 (1) | 2024.10.19 |
| [운영체제] 페이지 교체와 프레임 할당 (1) | 2024.10.19 |
| [운영체제] 페이징을 통한 가상 메모리 관리 (4) | 2024.10.19 |
| [운영체제] 연속 메모리 할당 (2) | 2024.10.19 |