안녕하세요, 혼자 공부하는 SQL를 보고 학습한 자료를 남깁니다.
데이터 형식
데이터베이스는 SELECT, INSERT, UPDATE, DELETE문을 수행하기 위해
데이터 형식을 제공을 합니다.
각 데이터 형식은 세분화되어 있습니다.
정수형 (소수점이 아닌 수)

INT는 가장 무난하게 사용할 수 있는 데이터 형식
하지만 예를 들어, 카카오톡에서는 이용자수가 5,000만명이 넘습니다.
나이를 INT로 저장을 하면 각 나이는 4byte를 차지를 하는데
5,000만 * 4byte를 하면 상상도 못할 정도의 용량을 차지하게 됩니다.
하지만 나이는 굳이 -21억부터 +21억까지 저장될 필요는 없습니다. 이와 같은 경우
TINYINT를 사용할 수 있습니다.

각 정수형 자료형은 다음과 같이 데이터를 저장할 수 있습니다.
확인 차원에서 테이블을 만들어 보겠습니다.
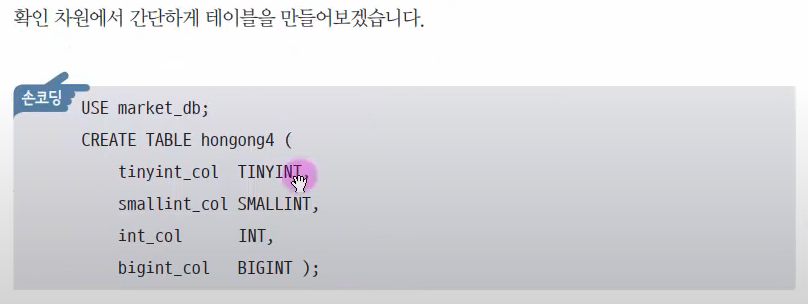

hongong4라는 테이블을 만듭니다.
TINYINT, SMALLINT, INT, BIGINT 이렇게 네 자료형을 각각 갖은 컬럼들을 갖은 테이블을 만듭니다.
그리고 최대값을 INSERT 해보고
최대값의 1을 넘긴 수들을 INSERT 해봅니다.
최대값을 넣은 경우네느 성공하였다는 것을 Output 창에서 확인할 수 있습니다.
하지만 최대값의 1을 넘긴 수는 오류가 발생한 것을 확인할 수 있습니다.

인원수는 현재 INT로 되어 있다. 하지만 INT는 최대 21억까지 된다.
그래서 TINYINT로 바꾸는 것이 좀 더 효율적이다.
그리고 키는 SMALL INT로 데이터 형식을 지정을 했는데 키는 -32768~32767까지의 저장공간이 필요가 없으므로 TINYINT로 바꾸어도 괜찮을 것 같다.

하지만 TINYINT는 -128~127까지는 키가 200이 넘는 경우도 있으므로
이를 UNSIGNED로 해결할 수 있다. 그러면 0~255까지 저장이 가능하다.

그러면 이렇게 mem_number를 TINYINT로 바꾸고, height은 TINYINT UNSIGNED로 바꿀 수 있다.
문자형

대표적인 문자형은 CHAR(개수), VARCHAR(개수)가 있습니다.

CHAR(10)과 VARCHAR(10)은 다르다.
CHAR(10)인 자료형에 3글자만 저장을 하면 공간이 낭비된다.
하지만 VARCHAR(10)인 자료형에 3글자만 저장을 하면 공간이 줄어든다. 공간을 효율적으로 사용할 수 있다.
하지만 CHAR로 설정을 하면 내부적으로는 빠른 성능(빠른 속도)를 내므로 CHAR로 설정하면 조금 더 좋습니다.
그래서 CHAR는 글자의 개수가 고정된 경우에 사용하는 것이 좋다.
VARCHAR는 글자의 개수가 변동될 경우에 사용하는 것이 좋다.
예를 들어 거주지역의 경우 정확히 2글자만 저장하도록 계획을 했다. 고정된 값을 저장하는 것이기에 그러면 CHAR(2)를 사용하는 것이 좋다.
하지만 방탄소년단이나 잇지 처럼 서로 다른 문자열의 길이가 들어가면 VARCHAR(10)로 저장하는 것이 좋다.

전화번호의 경우 더하기/빼기 또는 크다/작다가 의미가 없다. 그러면 문자로 취급을 하는 것이 좋다.
숫자로 한다고 해서 틀리지는 않는다. 효율성이 떨어진다. 의미가 없기 때문이다.
숫자의 모양을 하고 있지만 연산의 의미도 없고 크다/작다의 의미도 없다면 문자로 취급하는 것이 일반적이다.
대량의 데이터 형식

보다 더 큰 데이터를 저장하려면 다음과 같은 데이터 형식을 사용을 해야 한다.
대량의 데이터 형식 _손코딩 실습

big_table을 생성하려고 시도를 하는데 오류가 발생한다.
데이터 형식보다 더 큰 데이터를 저장하려고 했기 때문이다.

DROP문을 실행하여 다시 big_table을 다시 CREATE를 할 수 있다.

NETFLIX와 같은 데이터베이스를 만들어 보았다.
동영상 테이블이 있고 자막 테이블이 있다고 가정을 한다.
자막 VARCHAR(가변형 문자)로 잡아도 안 되고 동영상 BLOB(이진 데이터)으로 잡아도 안 된다.
그럴 때 지원하는 데이터 형식이 바로
LONGTEXT와 LONGBLOB이다.

실수형

FLOAT은 바이트 수가 4이다. (소수점 아래 7자리까지 표현)
DOUBLE은 바이트 수가 8이다. (소수점 아래 15자리까지 표현)
날짜형


DATE는 날짜만 그리고 TIME은 시간만 저장
예를 들어, 출퇴근 시간의 경우 DATETIME이 필요한 것이다.
변수


데이터베이스에서 변수는 워크벤치가 재시작할 때 까지는 유지되지만 종료하면 없어집니다.
그러므로 임시로 사용한다고 생각하면 됩니다.
간단한 예를 살펴보겠습니다.
SET @myVar1 = 5;
SET @myVar2 = 4.25;
@ + 변수명 = 대입할 값;
의 형식으로 변수를 선언하면 됩니다.
변수 선언_손코딩 실습

임시적으로 변수를 선언하여서 값을 사용할 수 있습니다.
SET 명령문을 통해서 변수를 선언하고 값을 할당할 수 있고,
SELECT문을 사용해서 변수의 값을 조회하거나, 계산을 하는 등의 변수간의 연산 결과 값이 조회가 가능합니다.
하지만 지금 접속된 root계정에서는 가능하지만, 다른 계정에서는 변수를 사용할 수 없다.
워크 벤치를 끄고 다시 실행을 하면 다음과 같이 @myVar1의 값이 조회가 안 된다.

변수는 현재 상황에서만 쓰는 임시적이다.


79번줄 코드와 80번줄 코드는 서로 같은 것이다.
변수에 해당 값들이 대입이 된 것이다.

LIMIT의 값에 변수를 대입을 해주려고 하면 되지 않는다.
이후에 오류가 발생하는 쿼리이기 때문이다.
그래서 미리 오류가 발생된다.

이와 같은 경우 PREPARE 명령문과 EXECUTE 명령문을 통해서 실행이 가능하다.
?에 @count의 값이 대입이 되는 것이다.
데이터 형 변환

데이터의 형변환이 필요하다.
우리가 명시적으로 데이터를 형변환 해줄 수도 있고, 암시적으로 데이터를 형변환 해줄 수도 있다.

다음과 같이 AVG() 함수를 사용해서 전체 컬럼의 평균값 조회가 가능하다.
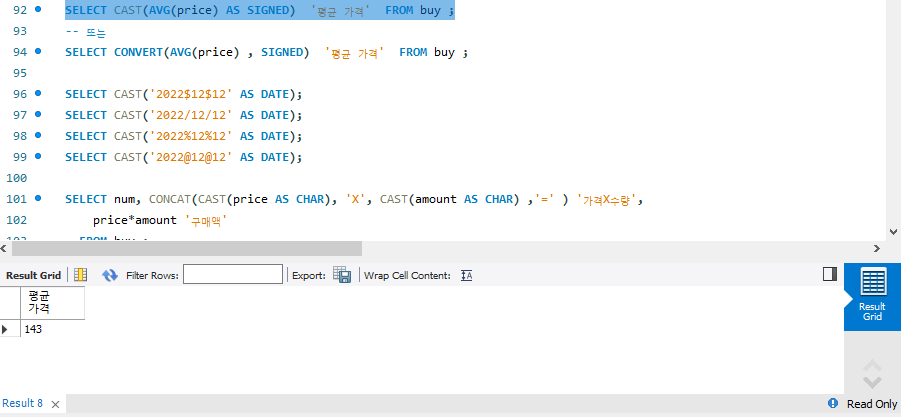
다음과 같이 CAST(AVG(price) AS SIGNED) 를 하면 평균값을 낸 해당 실수를 SIGNED 즉 부호가 있는 정수형으로 바꾸어라는 의미이다.
결과 값으로 평균가격 143이 출력된 것을 볼 수 있다.

CONVERT함수를 사용해서 실수형을 정수형으로 바꾼 것이다.

문자를 날짜 형식으로 바꾸는 것도 이와 같은 형식으로 사용이 가능하다.
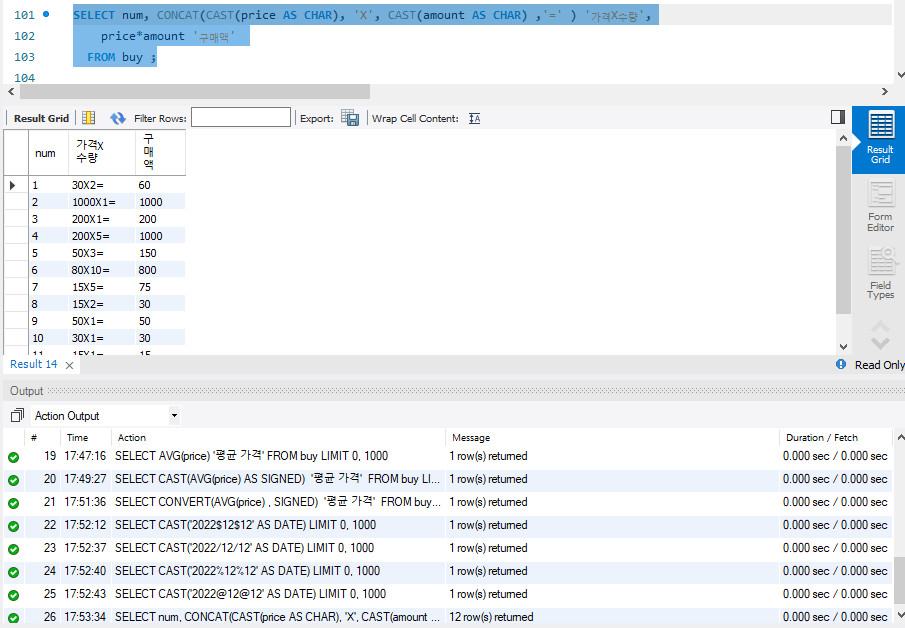
CAST함수를 통해서 price를 CHAR로, amount를 CHAR로 바꿀 수가 있다. 그리고 'X' 그리고 '=' 등의 문자들을 CONCAT() 함수를 통해서 서로 이은 것이다.
그러면 다음과 같이 결과가 출력되는 것을 볼 수가 있다.
암시적 형변환

SELECT '100' + '200' ; -- 문자와 문자를 더함 (정수로 변환되서 연산됨)
결과 값으로 문자열이 정수형으로 암시적으로 형변환 되고 + 연산자를 통해서 300이라는 연산된 결과값이 출력이 된다.

문자를 직접 잇고 싶다. 그러면 CONCAT()으로 처리하면 된다.

CONCAT(100, '200'); 은 정수와 문자를 연결하는 함수이기 때문에 정수가 문자로 변환되서 처리가 된다.

SELECT 1 > '2mega';
정수인 2로 변환되어서 비교가 된다.
1 > 2 의 결과값으로 0이 출력이 된다.

정수인 2로 변환되어서 비교가 된다.
결과값은 3 > 2 인 1이 출력된다.

문자는 0으로 변환된다.
0 = 0의 결과값으로 1이 출력된다.
감사합니다.
https://www.youtube.com/watch?v=1YmWy-7-OhQ&list=PLVsNizTWUw7GCfy5RH27cQL5MeKYnl8Pm&index=10
'SQLD' 카테고리의 다른 글
| [혼자 공부하는 SQL] SQL 프로그래밍 (IF문, CASE문, WHILE문, 동적 SQL) (0) | 2024.10.25 |
|---|---|
| [혼자 공부하는 SQL] 두 테이블을 묶는 JOIN(INNER JOIN, OUTER JOIN, CROSS JOIN, SELF JOIN) (0) | 2024.10.25 |
| [혼자 공부하는 SQL] 데이터 변경을 위한 SQL문 (INSERT, UPDATE, DELETE) (1) | 2024.10.25 |
| [혼자 공부하는 SQL] SQL SELECT 절의 형식 (ORDER BY 절과 GROUP BY 절) (0) | 2024.10.25 |
| [혼자 공부하는 SQL] SQL 기본 문법(SELECT~FROM~WHERE) (1) | 2024.10.25 |