* Youtube Link - https://www.youtube.com/watch?v=aAYU18AGyDg&list=PL6i7rGeEmTvpLoDkB-kECcuD1zDt_gaPn&index=11
01. 파티션 문제



MANAGER_ID를 파티션으로 나누어서 연봉으로 오름차순을 하고 처음 값 부터 누적계산을 하여
SUM(SALARY)를 도출해낸다.
이로써 또 다른 의미있는 데이터를 만들어낸다.
AND CURRENT ROW와 같은 결과가 나온다.

RANGE BETWEEN 10 PRECEDING AND 150 FOLLOWING을 하면
예를 들어 SALARY가 2500인 열은 SALARY가 2490부터 2650까지의 범위를 만들어내고
이를 파티션으로 COUNT(*)을 한 결과가 컬럼 TTT에 나오는 것이다.

ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING의 경우
예를 들어 SALARY가 6500인 경우
그 위의 행인 SALARY가 5800인 행과
바로 그 아래 행인 SALARY가 7900인 행 이렇게 3개의 행의 연봉의 평균값을 계산해서
결과를 도출하는 것이다.
02. 인라인 뷰 및 UNION

(1)이 정답이다.


(2)의 경우 문법적으로 오류가 난 경우이다.
group by salary로 하고 select 절에서 job_id를 조회를 하면
예를 들어 1500인 salary를 갖는 컬럼이 job_id를 2개 갖게 된다.
그래서 group by를 사용을 하면 사용할 수 있는 컬럼이 한정이 된다.
그래서 (2)은 정답이 아니다.

union all은 중복도 되지 않고 정렬도 되지 않는다.

union 기능이 sort unique였지만
오라클이 업그레이드 되면서 hash unique(중복제거+정렬 안할 수 있음)
으로 변경되었다.
03. CASE 문법의 종류와 CASE 문법의 NULL 연산


SIMPLE CASE 문법과
SEARCHED CASE 문법 이렇게 2개의 문법이 있다.

(1)의 경우
SIMPLE CASE 문이다.
WHEN NULL의 경우 '='의 연산을 하므로 NULL은 연산이 불가능하다. 그래서 함수를 사용해야 한다.
그래서 NULL인 컬럼은 else문인 0으로 출력된다.
NULL은 IS NULL 연산으로 연산할 수 있다.
DECODE() 함수는 NULL인 경우 -1. 아니면 있는 값 그대로를 배출하도록 만들어졌다.
예를들어 a.COL1이 NULL이면 -1 아니면 a.coll을 배출한다.
04. WHERE절 사용 방법
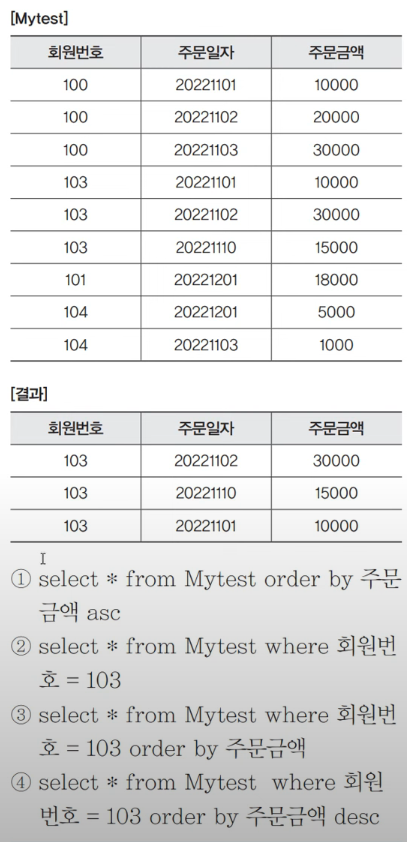
정답은 (4)이다.
(2)과 (4)의 다른 점은
정렬이 다르다는 것이다.
05. 데이터 입력 문제

숫자를 VARCHAR2(10) 데이터를 입력하려고 하면
형이 달라서 자기 형으로 바꿔본다. 그래서 TO_CHAR(002)를 한다.
그러면 '002'가 된다.
정답은 (4)이다.
숫자값을 DATE에 넣으려고 한다.
그러면 TO_DATE(20220420)을 하면 날짜 값으로 들어갈 수도 있다.
하지만 에러가 날 확률이 높다.
06. 여러 열 ORDER BY 문제

먼저 ORDER BY COL1 DESC를 한다.

그리고 COL2에서 같은 값들 중 COL3를 기준으로 정렬을 한다.
NULL은 제일 아래로 내려간다.
그래서 정답은

(3)이다.
07. 집계 함수

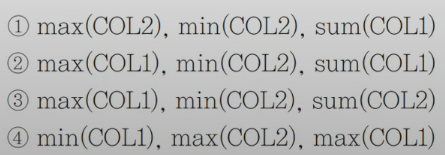
각 열을 집계해서 조회한다.
이렇게 다양한 컬럼들을 집계해서 조회할 수 있다.
정답은 (2)이다.
08. GROUP BY 활용

정답은 (3)이다.
각 계층별 결과를 정확히 알아야 한다.
GROUP BY DEPTNO, JOB: 이 경우는 전체를 GROUP BY한 결과가 나와선 안 된다.
GROUP BY GROUPING SETS(DEPTNO, JOB): JOB으로도 전체를 GROUP BY한 결과가 나와야 한다.
GROUP BY ROLLUP(DEPTNO, JOB): ROLLUP은 계층적으로 GROUP BY를 하여서 조회한다.
GROUP BY CUBE(DEPTNO, JOB): 모든 경우의 수를 GROUP BY하여 조회한다.
09. ORACLE을 ANSI 표준 SQL문으로 변환하는 문제


정답은 (4)이다.
10. 조인 문제

모든 경우의 수를 구하고
조인 조건에 맞는 결과만 조회한다.

카티션 조인이 된 순간 모든 경우의 수가 처리된 것을 볼 수 있다.

정답은 (1)번이다.
INNER JOIN은 키 값이 같은 결과만 조회한다.
LEFT OUTTER JOIN과 RIGHT OUTTER JOIN은 각각 키 값이 같지 않은 결과도 조회한다.
FULL OUTTER JOIN은 양 측의 테이블에서 키 값이 같지 않은 결과도 조회한다.
CROSS JOIN은 카티션 조인을 하여서 모든 경우의 수를 구한다. 예를 들어 4개 행과 3개 행을 곱해서 12개의 모든 경우의 수를 조인해서 조회한다.
감사합니다.
'SQLD' 카테고리의 다른 글
| [SQLD] 최신 기출문제 2회 (1~10) (3) | 2024.11.06 |
|---|---|
| [SQLD] 최신 기출문제 1회 (41~50) (7) | 2024.11.05 |
| [SQLD] 최신 기출문제 1회 (21~30) (5) | 2024.11.05 |
| [Youtube review] [SQLD] 최신 기출문제 1회(11~20) (4) | 2024.10.31 |
| [Youtube review] [SQLD] 최신 기출문제 1회 (1~10) (2) | 2024.10.31 |























